|
|
"To us
all towns are one, all men our kin. |

| Home | Whats New | Trans State Nation | One World | Unfolding Consciousness | Comments | Search |
|
|
"To us
all towns are one, all men our kin. |
| Home | Whats New | Trans State Nation | One World | Unfolding Consciousness | Comments | Search |
Home > Tamil Digital Renaissance > Tamilnet'97 > An Overview of Different Tools for Word Processing of Tamil and A Proposal Towards Standardisation - Dr. K. Kalyanasundaram
An Overview of
Different Tools for Word Processing of Tamil
and A Proposal Towards Standardisation
Dr.
K. Kalyanasundaram
Abstract
Tamil word-processing is currently done using a wide variety of Tamil font faces and specialised word-processors. The font-encoding scheme in all these tools are very different and so also the input/output mechanism of operation. This had to many practical difficulties in accessing Tamil based web pages on the Internet. In this paper we review many of such tools currently used for Tamil word-processing, classifying them under a unifying scheme based on the input/output features. This is followed by a proposal for standardisation of Tamil word-processing.
Introduction
Dravidian Languages such as Tamil use non-roman letters as alphabets. Typing of text materials in computers of these Indic languages requires use of either specific font-faces and/or word-processing software. In this paper, features of some of the most commonly used Tamil font faces and software are reviewed and a possible scheme towards standardization of Tamil Computing is also indicated. The term 'Tamil Computing' is used here in a narrow sense to cover the area of word-processing. Tamil Computing covers a much broader domain with applications in many areas: tools for larger databases of different kinds using Tamil script, multimedia kits for learning Tamil, multi-lingual dictionaries, translation software etc.
In the last two decades, many different font faces and
desk-top publishing (DTP) software have appeared for word-processing of Tamil
and along with them different typing (input) methods. Some of these are based on
simple recasting of the Tamil typewriter keyboard in the form of 7-bit fonts.
Others are sophisticated 8-bit font/word-processing packages where the actual
keystrokes and their relative sequence are interpreted to provide the required
Tamil texts. These packages allow different modes of input including
romanized/transliterated input. Font Encoding, i.e., the exact location of
different Tamil characters in the reference standard chart/ASCII table (128 or
256 slots) in the Tamil font being used determines the 'output' content of the
Tamil text irrespective of the mode of 'input'. Tamil text files created using
one font/DTP package cannot be read using another font unless the font encoding
scheme is identical between the two fonts in question.
Necessity for setting standards arises from the growing trend to exchange/share information between individuals placed in different parts of the world. There is a growing number of Tamil pages being put on the Internet/WWW using fonts and packages with different font encoding schemes. This has led to an unpleasant situation: One needs to acquire and install as many fonts as the number of Tamil web pages to be able to read them on the Internet. In the absence of any standard protocols by which the information storage is carried out at the font-encoding level, information exchange on a world-wide become too complex for many of the concerned individuals, if not impossible. Majority of the end-users (Tamil community at large) are not well-versed in technical aspects of data storage, transfer. So procedures have to be designed so that ordinary/common people can put up web pages and share information electronically in Tamil world-wide without getting involved too much into the technical nitty-grittys. Any proposals for standardization needs to accommodate the current typing habits/preferences (some kind of backward compatibility).
Transliterated/Romanized form of Tamil
By transliterated/romanized Tamil text, we refer to reproducing in a near-close phonetic form, the Tamil texts using roman alphabets. Thus, the Tamil word for father is written as appA (or appaa), mother as 'ammA' (or as ammaa). Transliterated form of reproducing dravidian language materials has been popular amongst western indologists for well over a century (pre-modern computer Era). Even standards were discussed and adopted in an international conference as early as 1888. The earliest and widely used transliteration scheme is what is known as LIBRARY OF CONGRESS TRANSLITERATION SCHEME. This uses roman alphabets with diacritics (horizontal bars or circles added above or below roman alphabets) to represent alphabets of indian languages.
Figure 1 shows pictorially this and other
transliteration schemes for Tamil discussed in this paper. Diacritical markers
added to a letter or symbol show its pronunciation, accent, etc., typically
indicating that a phonetic value is different from the unmarked state. The
scheme is very general in scope and hence can be used in almost all world
languages. Established Tamil research centres all around the world are aware of
this scheme and most of them implement this scheme as such without
modifications. In Chennai, Institute of Asian Studies (engaged in publishing
many of the Tamil literature related research) and Roja Muthaiah Tamil Research
Library [1] with links to Univ. of Chicago (involved in electronic cataloguing
of 50000+ precious Tamil books collections) are examples of institutions that
follow this scheme.

Given the practical constraints on the scope of present day electronic communications (largely 7-bit) alternate TRANSLITERATION SCHEMES BASED ON PLAIN ASCII CHARACTERS have also been in use widely. Figure 1 also includes some of the commonly used transliteration schemes of this kind. Plain ASCII scheme was considered in the early pre-computer era but was abandoned as being non-practical.
In the last two decades with the growing use of computers, there is an increasing number of individuals and institutions that employ some form of a 'transliteration scheme' based on plain ASCII roman characters. Presently most of the postings on the USENET Newsgroups of Internet such as soc.culture.Tamil quote Tamil texts in the form of romanized text, for display on plain ASCII terminals. MADURAI software [2] uses a code to construct Tamil alphabets on screen in four lines using ASCII letters.
Though it is not "print quality" it allows to convey the message in quasi-Tamil script. The classic 10-volume reference work "Tamil Lexicon" published by the Univ. of Madras during 1929-1939 used the transliteration scheme based on plain ASCII. The Institute of Indology and Tamil Studies of Univ. of Cologne (Köln) [3] uses this scheme for the cataloguing of their 50000+ Tamil books collections and also for their extensive collection of electronic texts of ancient Tamil classics (e.g., Sangam Literature).
As stated earlier, writing in the LC form of transliterated Tamil on Computers requires special fonts that contain roman letters with the diacritics. Library of Congress (LC) and major Tamil libraries in the USA and Europe allow on-line search of their catalogues from anywhere in the world. In order that searches can be made using simple ('dumb') terminals, on-line catalogues allow search using plain ASCII characters without the corresponding diacritical markers. Thus, one has to use keyword 'anil' for squirrel while searching LC or Univ. of California, Berkeley. But, at the IITS library of Univ. of Köln where the indexing is on alternate transliteration scheme (based on plain ASCII), the search would be as 'aNiL' ! Thus, here we have an anomalous situation where care has been taken to catalogue books using a special font (not readily available) but all its features are lost while doing search using plain ASCII characters. There is also the practical problem that one has to first educate oneself as to which form of transliteration scheme used at the place of search.
In view of the above points, it is essential that, some consensus be reached on a universally adopted transliteration scheme. As will be discussed below, there are now DTP software that allow 'input' in romanized text format. Here also it would be better if some standard form of transliteration scheme is universally adopted. Our preferences are for a scheme such as that used in Adhawin/Madurai, one that allow writing in near phonetically equivalent form but using plain ASCII characters.
Word Processing using 7-bit Tamil fonts (direct output)
Tamil typewriters have been in use for many years before the advent of computers. So it is logical that early approaches to Tamil computing involved implementing the classical typewriter in the form of 7-bit fonts. Various Tamil characters are placed under different roman letters at the equivalent locations of the Tamil typewriter. All of the Tamil alphabets are obtained by using the normal and shift-mode operation of the standard keyboard. While some of the alphabets are obtained in single keystroke, others are obtained by two or three keystroke operations. With such Tamil fonts, those who are accustomed to typing on Tamil typewriter can make the transition to Tamil computing without difficulty and loss of any typing speed. This trend is very strong in Tamilnadu even today. Majority of Tamil computing use the Tamil typewriter keyboard layout(s). So any Tamil Computing Standardisation efforts need to take this reality into account. There are many font faces of this type available: TAMILLASER of Prof.George Hart, ANANKU [4] of P.Kuppuswamy (widely used in continental US), SARASWATHI of Vijayakumar (widely used in Canada) are some examples. BHARATHI word processor for plain DOS computers was one of the early ones to appear (in early eighties) in Malaysia and Singapore region. VENUS is a recent, updated version of this word-processor running under Windows environment.
The common logic in any keyboard layout design is to have most commonly occurring letters placed in the central/middle part of the keyboard (and less frequent ones moved to left/right extremes). This concept/logic was applied quite a while ago in the design of typewriters. In Tamil, in good old classical Tamil typewriter layout, one particular assignment was chosen: middle line ya, La, na, ka, pa, modifier for aa, tha, ma, ta in middle line; nga, Ra, n^a, ca, va, Na, ra, sa, zha, modifier for i in the top line and ii, la, o, u, e, ti, modifier for e, a, i at the bottom line. There have been many re-examination of this concept of character placing for Tamil keyboard recently. Mohan Tambe of CDAC, Pune designed a keyboard layout for indic languages using such an analysis. Naa Govindasamy (host of this conference) has made similar analysis for Tamil and has designed the Kanian/IE/Singapore Tamil Keyboard layout [5].
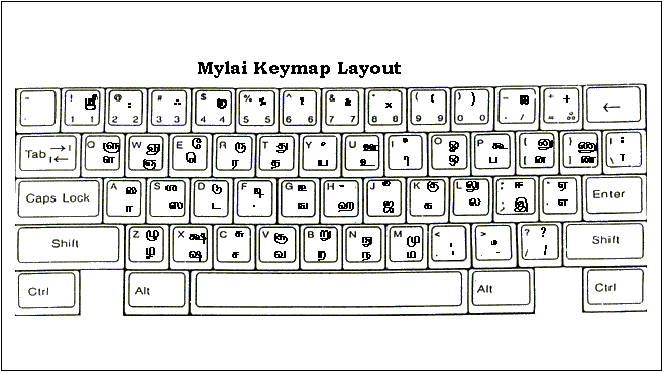
An alternative approach to Tamil typewriter keyboard layout involves phonetically linking Tamil characters to be typed to corresponding roman letters. Thus you hit the key k to get ka, m for ma, l for la, p for pa, k followed by i for ki, k followed by I to get kii and so on. For those who never used the Tamil typewriter, this approach can be intuitive and very appealing. Since Tamil characters of 7-bits are readily accessible via normal and shift-modes of the keyboard on all computers, I designed a 7-bit font called MYLAI that used a phonetically based input [6] (Figure 2) .
The term 'phonetic' is used in a slightly different context by
many (e.g. participants of this conference Naa Govindasamy, Ravindran Paul). So
we would use the abbreviation WYTIWYG (what you type is what you get) layout to
refer to keyboard layouts based on the above cited phonetic input method. The
frequency of occurrence of Tamil characters in Tamil need not necessarily be the
same as in English. So there were some reservations for sustained interest in
people to use keyboard layouts of the WYTIWYG kind. Surprisingly, the reception
to Mylai keyboard has been overwhelming. In the last three years, several
thousand Tamil lovers all around the world have received a copy of the Mylai
font and happily using it for Tamil computing. Some even wrote to say that, with
the satisfaction in Mylai, they have been deleted some Tamil font faces of
classical typewriter kind that they bought earlier for a price. It can be stated
that, Mylai was not the first Tamil font available free on the Internet (there
have been several others freely available) nor it gives the most aesthetically
pleasing print out for very demanding end-users.
Word-processing using 8-bit font faces (direct output)
If one counts the number of alphabets of Tamil, we have over 230 characters (13 vowels, 18 consonants and products (uyirmeis) derived from these. Tamil is one of the Indian languages where many of the compound (uyirmei) alphabets have complex geometric structure (glyph) of their own. In 7-bit fonts with 128 slots, nearly half of them are not available for placing Tamil characters ( first 32 slots reserved for control characters, 10 places for roman numeral and another 10 or 12 for various key punctuation marks). For the number of Tamil alphabets to handle, the remaining positions are rather limited. In 7-bit fonts, a number of compound/uyirmei letters are obtained simply by adding a modifier glyph to the parent consonant. Tamil typewriter uses this concept extensively. 'Kerning' is a technique that allows controlled fusion of two successive character. Unfortunately, kerning is not easily implemented on many computer platforms. Without kerning, the quality of the output for on-screen display and in print using such 7-bit fonts can be far from satisfactory, at least for commercial publishing houses. So, there have been efforts to go for fonts of the 8-bit type (256 slots available). 7-bit and 8-bit fonts have their own merits and demerits. We will return to this topic later on.
In the absence of kerning and other character control
features, in many of the software packages designed for publishing houses, many
of the Tamil uyirmeis with complex structural forms are included as such in the
upper ASCII part (128-255). This way aesthetic quality print can be ensured. In
the Macintosh OS, it is easy to access many of these characters in the upper
ASCII part using the 'option' and 'shift-option' keys. T. Govindaraj (of USA)
designed a 8-bit Tamil font for Mac called PALLADAM making use of this feature.
In this font design, Tamil alphabets ma, mu and muu, for example, are obtained
using the keys m, shift-m and option-m respectively. In Windows, one needs to
have the 'alt' key down and type in the three digit reference number of the
character in question preceded by a zero, as in 0172 or 0213. One needs to
remember these numbers to be able to type at reasonable speed. So keyboard
editors/managers are often used. With these keyboard editors, one can access any
character using any key irrespective of the font encoding scheme used.
RAMINGTON TAMIL (Figure 3) is an example of the 8-bit
extension of the classical Tamil typewriter keyboard. In addition to 26 slots
occupied by roman numerals (10) punctuation marks (11) and mathematical
operators (5), 78 Tamil characters are placed in the font face. On Windows-based
PCs, the alt-key is used to obtain those extra Tamil characters. Softwares with
this Ramington Tamil keyboard layout are sold by Softview Computers of Chennai
and used extensively by the publishers of Tamil Newspapers and Magazines of
Tamilnadu.

Word Processors based on romanized input (interpreted
output)
ADAMI [7] was one of the early Tamil word-processors for MS-DOS PCs produced by Dr.K. Srinivasan of Canada in early eighties (released in 1984 for CPM-80 computers) to recast such transliterated text into Tamil. The Tamil text is to be typed using a plain ASCII transliteration scheme. Upon compiling/execution of the linked macro, this romanized text page is recast on screen in equivalent Tamil. One needs to return to the romanized text mode to make the corrections if any. In a more recent version of this software called THIRU [7], the author provides a split screen, where the roman text being typed in the bottom half of the screen is continuously recast in the upper half in Tamil. ADHAWIN [7] is another recent implementation of the same software but for Windows-based PCs. The transliteration scheme used in MADURAI is a subset of that used in ADAMI/ADHAWIN. The software operation used here is part of a general classification scheme called "romanized input/interpreted output" package.
For those who never wrote extensively in Tamil (and beginners who are not sure of exact uyirmei to use in writing Tamil worlds, e.g. na/Na), word processors that allow transliterated input is attractive. Madurai [2], ITrans [8] and XLibTamil [9] are some of the popular softwares used in UNIX platforms (in north america) for Tamil word-processing. They are also used widely to make Tamil-related postings in USENET newsgroups. Used in conjuncture with corresponding meta-fonts and TeX-type word-processing extensions, high quality print-outs can be obtained for the Tamil texts.
MURASU [10], ANJAL word-processing packages widely used in Malaysian, Singaporean Tamil Newspapers and Magazines are the products of Muthu Nedumaran present at this conference. These packages belong to the group of "romanized input/interpreted output" tools. The inaimathi and related fontfaces used in these packages are of the 8-bit bilingual type. The first 128 (0-127) slots are filled by roman characters as in basic ASCII and the Tamil characters occupy the upper ASCII slots (128-255). By invoking the keyboard editor it is possible to access either of these two blocks. In the Tamil typing mode, the roman keyboard strokes and their relative sequence are continuously interpreted to present equivalent Tamil characters on screen. Thus you type 'kathai' to get the equivalent Tamil word.
Word Processors based on phonetic keyboard input (interpreted output)
There are now available intelligent Tamil word-processors where the large number of uyirmei alphabets are obtained by a sequential keying of the corresponding mei and uyir characters. Thus the keystrokes for consonant k followed by vowel i leads to appearance of compound character ki. Keyboard layouts of this kind have been called "phonetic". There are no characters for kokki's kombu's etc. The keyboard driver does the mapping and remapping based on the sequence of keypress events. An advantages of this approach is that the number of keys to use to get all the uyirmeis are considerably less. Mohan Tambe (formerly of the Centre for Developments for Advanced Computing CDAC) was one of the early pioneers working on the keyboard layouts appropriate for Indian languages.
His phonetic keyboard layout known as INSCRIPT was initially designed (in 1983) for Devanagari script input. This has been adopted for use in the multi-lingual word-processors CDAC developed for Indian languages (cf. references to CDAC and Inscript in the next section). THUNAIVAN [11] word-processor of Ravindran Paul, IE PHONETIC KEYBOARD LAYOUT [5] of Naa Govindasamy, CHARACTER PHONETIC DEPENDENCIES/YARZAN [12] keyboard editor of R. Shanmugalingam are different forms of implementation of this phonetically based keyboard input concept. When compared to wytiwyg keyboard layouts, phonetic layouts reduce considerably the number of keystrokes required to get the o-kara, oo-kara, ou-kara uyirmeis.. Here you will type k followed by o or O. Two keystrokes give 3 characters. NALINAM [13] is another 8-bit bilingual Tamil word-processor distributed freely on Internet by Sivagurunathan Chinniah of Malaysia.
Place of Tamil in Multilingual word processing packages
Thanks to advances in the design of faster memory chips and compact high capacity storage devices, computers with GBs of storage (hard disc), MBs of RAM memory and high speed (>200 MHz) are already available at very affordable prices for the general public (at least in the western world, if not in India). To make full use of this capability, multilingual packages are being developed that allow preparation of documents containing scripts of more than two or three languages. Several thousand characters corresponding to ten or more languages are bundled up in a single 'super-font' and appropriate software allows selection of one of these languages from a pull-down menu.
The viability of this approach has already been demonstrated in the multi-language kit covering all the European languages, Greek and Turkish for Windows 95/NT environment. Microsoft [14] currently distributes 'free' a font face containing 800+ characters and also a software to use along with it. Indian languages are not yet included in this multi-language kit of Microsoft. MTSCRIPT [15] (developed by Univ. of Aix-en-Province under support of French CNRS) is a multi-lingual text editor (for UNIX running Solaris) that enables using several different writing systems (Latin, Arabic, Cyrillic, Greek, Hebrew, Chinese, Japanese, Korean, etc.) in the same document. All of the languages defined in the ISO 8859-X schemes are supported in this package.
Unicode Consortium [16] is currently working on a world-language standard character set (ISO 10646) for future use for multi-lingual word-processing. Unicode 2.0 version currently under discussion proposes specific slots character assignments for world languages including all Indic languages (Devanagari, Gurmukhi, Tamil, Telugu, Malayalam, Kannada,....). Muthu Nedumaran's paper at this conference dwells in to the details of implementation of this Unicode package. So we will not go into its detail except make a few remarks on the implications of the proposed character set (font encoding scheme). It was mentioned earlier, that, 8-bit fonts allow a large Tamil alphabets (100 or more) stored in their native form and this in turn allows high quality production of printed Tamil texts required for commercial publications. Unicode character set for Tamil has the bare minimum (64)- vowels, consonants, Tamil numerals and a handful of modifiers to add to the consonants to get the compound (uyirmei) characters. None of the uyirmeis have been allocated any slot.
If one uses only the above minimal character set, many of the uyirmeis have to be written in new forms (e.g., write pu, mu, puu, muu using the same right modifiers that are added to grantha letters ha/sa to get hu/su or huu/suu). Writing many of the uyirmeis in this new form (and deleting all the currently used structural forms/glyphs) in essence, amounts to introducing drastic language reforms - reforms in the way the script of the language is written currently.
In a parallel development to Unicode, the Dept. of Electronics of the Govt. of India has been developing standards for computing in Indian Languages (including Tamil) for over a decade. The primary tool is Graphic and Intelligence based Script Technology (GIST), a phonetic based computing technology. Center for Development for Advanced Computing (CDAC) based in Pune is the organisation in India engaged in developing multi-lingual computing tools based on the GIST technology. Mohan Tambe (working initially at IIT, Kanpur, later as the Head of the GIST group at CDAC, Pune) is the brain behind the major multi-lingual computing projects for Indian languages in India. The 1986 proposals of DOE for possible font encoding standards were revised by the Govt. of India in 1988 and were adopted as the 'national standard' under the name "Indian Standard Code for Information Interchange (ISCII-88). The early version of the Unicode apparently was modelled on the ISCII-88 standard.
As in the Unicode scheme, the basic characters defined in the ISC character set is graphics characters as (in Hindi) Anuswar, Visarg, a set of vowels, set of consonants and vowel signs. The display rending and formation of conjuncts is left to the software meant for such purpose. Along with the ISCII standard for font encoding, the "phonetic keyboard layout" of Mohan Tambe has been adopted under the name INSCRIPT as the national standard for keyboard layout. The GIST technology works in the 8-bit mode where the Tamil (or any Indian language ) characters are placed in the upper ASCII slots 160-255 (actually 79 characters/glyphs). The entire lower half and the line drawing character set in the upper half are left undisturbed for English so that bilingual documents consisting of English and the Indian language can be readily prepared. CDAC markets several products for multi-lingual computing based on this GIST technology.
The phonetic/inscript keyboard designed by Mohan Tambe is used in all of the CDAC/GIST packages. Apex Language Processor (ALP), ISM (ISFOC Script Manager), LEAP (Language Environment for Aesthetic Publishing) are some of the multi-lingual word processors sold by CDAC directly or through its franchises. Popular word-processing package SHREE LIPI of Modular Systems is another commercial version of the package. LEAP is a multiscript word processing package for windows (like MS-WORD) that allows comparing texts in all Indian languages. This is a cost effective solution for marketing/advertising agencies where trade literature giving details of the products can be given in all Indian languages one after the other. Apple has released very recently for Macintosh computers [17], a premier version of its 'INDIAN LANGUAGE KIT (ILK)'. This package contains fonts/software for word-processing in Devanagari and Gurmukhi. It has been stated that the ILK package is modeled on the ISCII standards of the Govt. of India.
ComStar [18] of Cupertino, California, USA markets multi-lingual Word Processors called GAMMA UNITYPE and UNIVERSAL WORD FOR WINDOWS that allows preparation of a multi-lingual text and the package supports a large number of world languages including Tamil. WordMate (also of ComStar, Inc) is a multi-lingual versatile software /keyboard driver that enables the user to type any of a long list of languages directly into virtually any windows application.
The Multilingual directory of the Internet [19] lists the following software currently available for multi-lingual word-processing including Tamil: Allwrite (of ILECC), Chitralekha (of Modular systems), Apex Language Processor (ALP) and ISM (ISFOC Script Manager of CDAC, Pune), Amicus (of Amicus), Gamma UniType and Multilingual Scholar (of Gamma Productions), Kalam (of Solustan Inc), LEAP (Language Environment for Aesthetic Publishing, of CDAC, Pune), Prakashak (of Sonata), Swadesh(of Institute for Typographical Research), Vision Publisher (of Vision Labs). Proposals for standardisation/font encoding for Tamil should taken into account the mode of functioning of these multi-lingual word-processors elaborated above. It would be unwise and non-practical to have different world standards for Tamil - one for mono/bilingual usage within the 8859-X scheme and one for multilingual packages.
Classification of tools for Tamil Word Processing
Functioning of any word-processor can be divided into two parts - those connected with the 'input' process and those with the 'output'. Based on the features of the input, output processes involved it is possible to classify all word-processing tools into following categories: i) classical typewriter input/Direct output ; ii) wytiwyg ("what you type is what you get") input/direct output; iii) romanized input/interpreted output ; iv) phonetic input/Interpreted output. Table 1 lists examples of different font faces and word-processing software grouped according to the above classification.
Table 1: A classification of
various tools available for Tamil word-processing.
| Name | Author | Type | Platform,Remarks |
| Fontfaces | |||
| [ananku] | P. Kuppuswamy | direct/ttw classical-1 | win/mac,7-bit |
| tamillasr | George Hart | direct/ttw classical-1 | mac, 7-bit |
| [saraswathi] | Vijayakumar | direct/ttw classical-1 | win, 7-bit |
| [TMNews] | (dinamani) | direct/ttw classical-2 | win, 7-bit |
| [amudam] | (softview comp.) | direct/ttw classical-3 | win, Ram.ttw |
| mylai | K. Kalyanasundaram | direct/wytiwyg1 | win/mac/unix, 7-bit |
| mylai-sri | K.Srinivasan | direct/wytiwyg1 | win,mac, 7-bit/ |
| palladam | T. Govindaraj | direct/wytiwyg2 | win,mac, 8-bit |
| valai-sri | K. Srinivasan | direct/wytiwyg3 | wind, 7-bit |
| trutamil | Raja Seshadri | direct/wytiwyg4 | win, 8-bit? |
| Word Processors | |||
| anjal/murasu | Muthu Nedumaran | interpreted/romanized1 | win, unix, 8-bit |
| adhawin/Adami | K. Srinivasan | interpreted/romanized2 | win, 8-bit |
| [nalinam] | Sivaguru Chinniah | interpreted/romanized3 | win, 8-bit |
| ITrans | Avinash Chopde | interpreted/romanized4 | Unix/win, 8-bit |
| XLibTamil | G. Swaminathan | intepreted/romanized4 | Unix, ? |
| madurai | Bala Swaminathan | interpreted/romanized2 | unix/PC, ? |
| PCTamil | Vasu Ranganathan | interpreted/romanized3 | DOS PC, ? |
| [IE/phonetic | Naa. Govindasamy | interpreted/phonetic1 | win/mac/unix, 8-bit |
| [Thunaivan] | Ravindran Paul | interpreted/phonetic2 win, 8-bit | |
| [Yarzan] | Shanmugalingam | interpreted/phonetic3 | win, 8-bit |
| [LEAP] | CDAC | interpreted/phonetic4 | win, 8-bit |
| [Gamma UniType | ComStar | interpreted/? | win |
| bharathi | ? | interpreted/? | DOS PC |
| venus | ? | interpreted/? | win |
Examples of 'Direct' tools are font faces used with associated keyboard layouts in typewriter or WYTIWYG format. In direct usage of simple font faces, the 'output' has a one-to-one correspondence with the input. For every keystroke, there is a character output. There is no software interpretation or intervention of the keystrokes. What letter you see on screen depends on what letter is stored under the keystroke in question. In other elegant word-processors, the 'input' is 'interpreted' by the software to give the output. The input can be in the form of romanized text or phonetically based. In all cases, keyboard editors/managers allow some manipulation of the input process. 'Font-encoding' determines the final 'output'.
A primary requirement for any standardisation process is to have a standard font encoding scheme. Irrespective of the mode of input and the output modes, all word-processing tools must use this unique standard character set. With such a unique font encoding standard, it is enough to have one single Tamil font/word processor to exchange Tamil documents electronically (including via WWW pages of Internet). In any implementation of standards, there is genuine fear on the part of end-users to know how much of their current typing habits and word-processor capabilities are to be sacrificed. Is it possible to find methodologies by which different typing habits ('input' practices) of end-users and also the choice of different modes of inputs be guaranteed within such a scheme imposing a standard character set (font encoding scheme)? The answer is yes. The details are elaborated in the following paragraphs.
Keyboard Layouts and associated Editors/Managers
Keyboard Editors (or Managers) allow access of any character stored in the font-face by typing any key on the keyboard. Different keyboard layout can handle typing preferences of individuals. As an end-user/laymen, we do not care where ku is assigned in the ref. table. But we would like to know which key on the keyboard we should use to get ku, ki and so on. Keyboard layout is what controls this access pathway and hence this is an important point that affects the end-user drastically. Both on Windows and Mac OS, standard keyboard layout software come with the system. These allow us to choose different layouts for typing in different European languages.
In French, for example, there are at least 4 different keyboard layouts available (French, French-numerical, Swiss French, Canadian French). Here in the French speaking part, we set my Mac/PCs to use Swiss-French keyboard layout and switch to US keyboard layout whenever typing is done in Tamil using Mylai Tamil font. Switching between keyboard layouts is rather trivial (even our 8-year old daughter knows how to change-to go from one keyboard to the other). (In French French keyboard, common French letters like e(accent grave), e(accent acute) etc. are in normal numerals key positions and you need to use shift to get the roman numerals themselves!!). Different keyboard layouts present different characters at key positions of choice. Thus the same font face set can be accessed differently on the keyboard using different layout schemes.
In Tamil, we can have different keyboard editors that allow us to do the same thing. Anjal, for example, can have different keyboard layouts made available to allow Tamil typing corresponding to different typing habits. In fact, Muthu Nedumaran is working towards providing a Mylai keymap typing option in future versions of Anjal. In principle, we can have many Tamil keyboard layouts (as is the case mentioned earlier for French) to satisfy every interest. The Summer Institute of Linguistics of Dallas, Texas, USA [20] makes available already in public domain a handful of software that allow development of dedicated keyboard editors/drivers for windows (e.g., KeyMan) and Macintosh (SILKEY) platforms. It is desirable though, to limit the number of keyboard layouts to make the life of software designers easier. Too many keyboard options means the software have to be adopted to handle different schemes.
A Proposal Towards Standardisation
In the introductory section of this paper it was pointed out that Internet is rapidly becoming a main channel/forum for exchange of information worldwide and that currently, Tamil on Internet is in a rather messy situation. Why? The Indian Government might have proposed a standard character set (ISCII) and a keyboard layout (INSCRIPT) for Indian languages nearly a decade ago. However the existence of these standards were not popularised outside India. Due to lack of communications, dedicated software for Tamil word-processing have been developed independently in India and abroad (particularly in Malaysia/Singapore region where there is a high concentration of Tamils).
Many of these software have their own novel features. Even if the number of Tamil-speaking community outside India may be less than those within India, major fraction of the former group have access to computers. Tamil computing is fast catching up in this group. Due to varying font encoding schemes used in the word-processing tools currently employed, the web pages require prior downloading of as many fonts as the web pages to browse. Along with the use of software comes the typing habits of individuals. In order to make information exchange of Tamil materials via Internet a real pleasure for all of us, it is essential that efforts are taken to unify these different approaches under some umbrella scheme.
It was mentioned earlier that, for a given font, different keyboard layouts can be presented to the end-user through the use of keyboard editors/managers. Given this possibility, one possible approach towards standardisation is to go for a single font encoding (standard character set) to be adopted in all Tamil font faces, word-processors and DTP packages. Each font/DTP package can come with different options of input methods provided in the form of different keyboard layouts made available under a pull-down menu. The feasibility of having keyboard editors/managers for some of the commonly used input methods has already been shown. Thus standardisation process reduces to deciding on a standard character set with some recommendations on possible keyboard layouts that can be provided for users' choice. Since end-users can continue to work with their own favourite keyboard layout, there will not be any major resistance to the implementation of this standard. The major task will be for the software developers to recast their existing font faces to correspond to one standard encoding scheme and provide appropriate keyboard editors/managers that are currently used. With the option available for anyone to test out different keyboard input methods, there can be hope to reduce the number of these layouts (weed out some less popular ones).
Implementation/large scale acceptance of proposed standards in a short span of time is possible if and only if the implementation process does not get bogged down with legal constraints imposed by copyright protections and associated high costs to obtain rights of usage of the technology involved in the standardisation process. Clearly, any scheme for font encoding or keyboard layout that is not strictly in public domain can cause problems. Open standards for all the key elements is critical. Recommending possible standards for world-wide Tamil computing that are based on propriety materials of few author(s) amounts to patronising and against all free market practices. To facilitate the process and to avoid ambiguity, it is highly desirable that all key players (software developers) in the field openly declare their consent to work within such "open standards framework".
A possible standard character set under 8859-X scheme
Currently most of the world languages are handled under different standard character sets registered with International Standards Organisation (ISO) under different headings. ISO 8859-X of ECMA (European Computer Manufacturers Association) is the most popular of these schemes for handling European and other languages of the world. It is currently implemented by the commonly used web browsers. So, in short, it is a proven technique.
The standard (default case for most web browsers) is 8859-1 and this supports most of the languages of Europe and Latin America. 8859-2 (aka as Latin-2) is designed for Eastern European languages, 8859-3 (aka as Latin-3) is designed for South-Eastern Europe, 8859-4 (aka as Latin-4) for Scandinavia (also covered by 8859-1), 8859-5 for Cyrillic/Russian, 8859-6 for Arabic; 8859-7 for Greek, 8859-8 for Hebrew, 8859-9 (aka as Latin-5) is same as 8859-1 except for Turkish instead of Icelandic and 8859-10 (aka as Latin-6) for Eskimo/Scandinavian Languages. For those who would like to know more about these standard character sets, there are a couple of web sites providing additional information: ISO Alphabet Soup [21] ; Information on ISO-8859 [22] and Internationalisation [23].
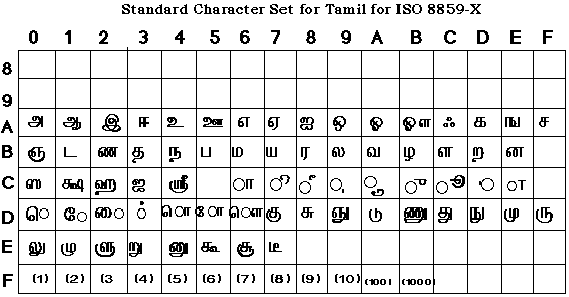
Herein, we would like to discuss a possible standard character set for Tamil
for eventual registration under the existing ISO 8859-X scheme. Figure 4
presents one possible standard character set following the general pattern of
8859-X schemes. The character set contains a minimal set of characters or glyphs
that one would need to be able to type Tamil texts in a form that will be
acceptable to majority of the Tamil community. It is modelled on the 7-bit Tamil
font faces of the classical Tamil typewriter and 'wytiwyg' keyboard layouts.
Tamil texts can be written in all of the possible current writing practices and
also in forms corresponding to some recent proposals suggesting reforms in Tamil
writing practices.
The time of introduction of standards for Tamil computing can also be an opportunity to introduce some of the proposed reforms in Tamil writing practices. Any reform/revision should be gradual to have a quick world-wide acceptance. Standards proposing drastic reforms will remain on paper and people will continue to write the way they do now. Hence we have to be very careful in deciding the content of the standard character set: number of glyphs Unicode 2.0 and ISCII Standards contain a minimal set of Tamil character glyphs (basic vowels, consonants and a handful of modifier glyphs that add to consonants to give the uyirmeis).
The actual generation of the uyirmeis is left largely to the software. If there are no standards on the actual number of glyphs to be used in Tamil word-processing, the output will be software dependent. All the proposed exercise of standardisation will be useless. As mentioned earlier, most of the uyirmei alphabets of Tamil language have their own unique geometric shape/glyphs. Currently most of the 8-bit word-processors designed for professional publishing houses (Tamil newspapers, magazines,...) keep these unique uyirmei glyphs within the 256 character set slots. If we do not specifically include these unique glyphs (many are not easily obtained using the kerning techniques), these schemes necessitate writing Tamil in a new radically revised form!!! To ensure backward compatibility and ready world-wide acceptance, the proposed scheme includes many of these unique uyirmeis as such. We are fortunate that, two other paper presentations at this conference (of Muthu Nedumaran and Anbarasan) will address specifically the Tamil standards as envisaged under the above UNICODE and ISCII standards respectively.
Acknowledgment
Many of the points discussed in this paper were floated and extensively debated in the Internet email discussion forum 'Tamil.net' during the last couple of months. I would like to thank Mr. Muthu Nedumaran and Mr. Bala Pillai for making this forum available and Muthu in particular for many fruitful dialogues during the past year. I would like to thank all those who participated in these discussions.
References
(Given are URL pointers to Web pages where detailed information on various tools can be obtained)
1. http://www.lib.uchicago.edu/LibInfo/SourcesBySubject/SouthAsia/RMRL.html (Roja Muthaiah Tamil Library)
2. http://www.geocities.com/Athens/9287/TS1.html (Madurai)
3. http://www.geocities.com/Athens/9287/TS1.html (Institute of Indology and Tamil Studies, Univ. of Cologne, Germany)
4. http://members.aol.com/kalvi/kalvi.htm (Ananku)
5. http://irdu.nus.sg/Tamilweb (IE phonetic Keyboard)
6. http://www.geocities.com/Athens/5180/mylai1.html (Mylai)
7. http://www.geocities.com/Athens/7444 (Adami, Thiru, Adhawin)
8. http://www.paranoia.com/~avinash/itrans.html (ITrans)
9. http://www.geocities.com/Athens/9287/TS2.html (XLibTamil)
10. http://www.murasu.com (Murasu/Anjal/Inaimathi)
11. http://itstation.com/thunaivan/thunaivan.html (Thunaivan)
12. http://www.tsnh.com/cpd.htm (Yarzan/CPD)
13. http://www.au.malaysia.net/Tamil (Nalinam)
14. http://www.microsoft.com/truetype/fontpack/default.htm (Microsoft fonts)
15. http://www.lpl.univ-aix.fr/projects/multext/MtScript/ (MtScript)
16. http://www.unicode.org (unicode)
17. http://www.macos.apple.com/multilingual/indian.html (Apple ILK)
18. http://www.gy.com (Comstar)
19. http://www.knowledge.co.uk/xxx/mpcdir/book.htm (Multilingual directory)
20. http://www.sil.org/computing/ (SIL)
21. http://wwwwbs.cs.tu-berlin.de/~czyborra/charsets/ (ISO alphabet soup)
22. http://ppewww.ph.gla.ac.uk/%7Eflavell/iso8859/iso8859-pointers.html (8859-x)
23. http://www.vlsivie.tuwien.ac.at/mike/i18n.html (Internationalisation)
Figures
1. Library of Congress and other Transliteration schemes for Tamil.
2. A schematic presentation of Mylai/Wytiwyg keyboard layout
3. A schematic presentation of Ramington Tamil keyboard layout
4. A possible standard character set for Tamil under the ISO 8859-X scheme
Email [email protected]
Institute of Physical Chemistry,
Swiss Federal Inst. of Technology, Lausanne, SwitzerlandDr. K. Kalyanasundaram is a native of Madras (oops, Chennai), Tamilnadu where he had his early school, university education. He attended Loyola College affiliated to the University of Madras, from where he received his B.Sc, M.Sc degrees in Chemistry. This was followed by doctoral thesis research in the area of photochemistry done at the Radiation Laboratory of the University of Notre Dame in Indiana, USA (received Ph.D in Physical Chemistry in 1976). After spending nearly 27 months in London, UK as a post-doctoral research fellow of the Royal Institution of Great Britain, he moved to his present location of Lausanne, Switzerland in 1979.
He is a member of the teaching and research staff of the Chemistry Dept. of the Swiss Federal Inst. of Technology (Ecole Polytechnique Fédérale, as it is known locally in the French speaking part of Switzerland). While surfing the Internet for a couple of years, he came across the huge amount of electronic archives of ancient literary classics in English. When he could not find anything worth talking about in Tamil available on the Internet, he floated an idea of a 'Tamil Electronic Library' in 1994 to the soc.culture.Tamil newsgroup. To facilitate electronic text archiving he developed a Tamil font called Mylai and has distributed several thousand copies of this font free via Internet. With this font as the base, he started building a collection of etexts of Tamil literary classics and the Tamil electronic library web site Thus grew his interests to various aspects of Tamil Computing and its Resources on Internet.